Reconocimiento de Objetos en la Web: El Poder de TensorFlow.js y Keras
Este post es la continuación de: Reconocimiento de objetos usando TensorFlow.js y Keras
La Inteligencia Artificial (IA) ha dejado de ser un concepto futurista para convertirse en una herramienta práctica y accesible para desarrolladores web. Gracias a bibliotecas como TensorFlow.js, ahora es posible llevar el poder del aprendizaje automático (Machine Learning) directamente al navegador, permitiendo crear aplicaciones interactivas que pueden entrenar y ejecutar modelos de reconocimiento en tiempo real, sin necesidad de servidores.
El código base de esta aplicación web es un claro ejemplo de cómo la IA en el navegador puede empoderar a los creadores. Este sistema permite a un usuario final no solo reconocer objetos, sino también entrenar su propio modelo con datos personalizados, todo desde la comodidad de su cámara web.
Este es el resultado de la version 1.0.0, pruébala en tu pc online aquí: IA de reconocimiento de objetos: TensorFlow.js y Keras
¿Qué son TensorFlow.js y Keras?
Para entender cómo funciona este código, es crucial conocer sus dos pilares principales:
- TensorFlow.js
Es una biblioteca de código abierto de Google que permite a los desarrolladores de JavaScript construir y entrenar modelos de aprendizaje automático directamente en el navegador o en Node.js. Esto es revolucionario porque aprovecha el poder de la tarjeta gráfica (GPU) del dispositivo del usuario, liberando a los servidores de la carga de procesamiento y permitiendo aplicaciones que funcionan sin conexión a internet.
- Keras
Originalmente una API de alto nivel para TensorFlow en Python, Keras se integra en TensorFlow.js a través de la capa @tensorflow/tfjs-layers. Su principal ventaja es que simplifica la creación de redes neuronales, proporcionando bloques de construcción intuitivos. En este código, Keras se utiliza para definir la arquitectura de la red neuronal convolucional (CNN), un tipo de modelo ideal para el procesamiento de imágenes, sin tener que lidiar con las complejidades de bajo nivel.
En conjunto, TensorFlow.js y Keras nos dan la capacidad de crear una aplicación completa y autocontenida que maneja la captura de datos, el entrenamiento del modelo y la inferencia (el proceso de reconocimiento) en el mismo lugar: el navegador web.
Diagrama del Proceso de Entrenamiento y Predicción
El proceso de esta aplicación sigue un flujo lógico:
- Captura y Etiquetado de Datos: Antes de que un modelo pueda reconocer algo, necesita ser «entrenado» con ejemplos. Para que una IA aprenda a reconocer algo, necesita ver muchos ejemplos. La aplicación te pide que le des un nombre a un objeto (ej. «Vaso») y que captures una serie de fotos desde tu cámara. Cada foto se convierte en un tensor de datos y se asocia con la etiqueta que le asignaste (ideal tomar más de 200 fotos desde todos los angulos, diferentes tipos de iluminacion, diferentes fondos, incluso debes de tener en cuenta si el objeto está siendo sostenido en tus manos) lo id. Este conjunto de imágenes y etiquetas es el «dataset» de entrenamiento.
- Entrenamiento del Modelo: Una vez que tienes suficientes imágenes de al menos dos objetos diferentes, la aplicación utiliza Keras para construir un modelo de CNN. Este modelo se entrena iterando sobre las imágenes capturadas, ajustando sus pesos internos para aprender a distinguir entre los diferentes objetos. Después de cada «época» de entrenamiento, el modelo se vuelve más preciso.
La CNN se encarga de aprender automáticamente las características más importantes de las imágenes, como los bordes, texturas y formas, para diferenciar entre los objetos que le mostramos.
La imagen representa la arquitectura de una Red Neuronal Convolucional (CNN), que es el tipo de modelo que se entrena en la aplicación.
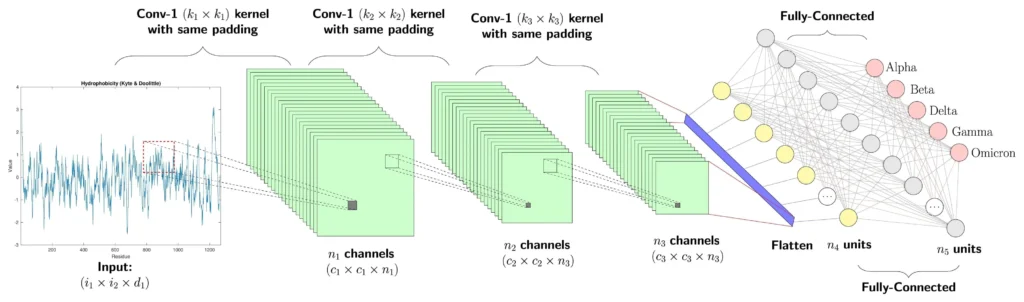
Una CNN es un tipo de red neuronal especializada en el procesamiento de datos con una estructura de cuadrícula, como las imágenes. Funciona de manera similar al cerebro humano, que identifica objetos reconociendo una jerarquía de características: primero los bordes, luego las formas, y finalmente los objetos completos.
Aquí te explico las principales capas que ves en el diagrama:
Capas Convolucionales
Estas son el «corazón» de la red. Su trabajo es examinar la imagen pixel por pixel, buscando y extrayendo características o patrones. Imagina que cada capa es como un detector que busca algo específico: una capa puede buscar bordes horizontales, otra bordes verticales, y otra más, texturas o colores. Al final de esta fase, la red ha creado un mapa de características detallado de la imagen.
Capas de Agrupamiento (Pooling)
Después de que las capas convolucionales han extraído las características, las capas de agrupamiento (como maxPooling2d en el código) actúan como un compresor de datos. Su función es reducir el tamaño de los mapas de características que se generaron, manteniendo solo las más importantes. Esto hace que el modelo sea más rápido y menos propenso a errores, ya que se centra en las características dominantes y no en detalles insignificantes.
Capa de Aplanamiento (Flatten)
Después de varias rondas de convoluciones y agrupamientos, el modelo tiene un conjunto de mapas de características reducidos. Sin embargo, estas aún tienen una estructura 2D. La capa de aplanamiento (flatten) convierte esta estructura 2D en una sola línea de datos 1D. Piensa en ella como una capa que prepara la información para la fase final de toma de decisiones.
Capas Densas
Una vez que los datos han sido aplanados, pasan a una o más capas densas. En estas capas, cada neurona está conectada a todas las neuronas de la capa anterior. Es aquí donde ocurre la clasificación final. El modelo utiliza los patrones que ha aprendido para determinar la probabilidad de que la imagen pertenezca a cada una de las clases que entrenaste (por ejemplo, «Vaso», «Lápiz», etc.). El resultado final es la clase con la probabilidad más alta.
- Predicción en Tiempo Real: Con el modelo entrenado, la aplicación entra en un bucle de predicción. Continuamente captura un cuadro de la cámara, lo pasa al modelo, y este devuelve una probabilidad para cada objeto que ha sido entrenado. La aplicación muestra el nombre del objeto con la probabilidad más alta, permitiendo el reconocimiento en tiempo real.
Análisis del Código JavaScript
El corazón de esta aplicación es el código JavaScript, que orquesta todo el proceso. A continuación, se explican sus funciones principales:
- init():
Esta función es el punto de entrada de la aplicación. Se encarga de inicializar la cámara web del usuario y de preparar el entorno para la captura de imágenes. La línea clave webcam = await tf.data.webcam(videoElement); utiliza TensorFlow.js para crear una interfaz de datos a partir del video, lo que facilita la captura de fotogramas para el entrenamiento y la predicción.
async function init() {
try {
statusElement.textContent = 'Inicializando cámara...';
// Inicializa el objeto de la cámara web
if (navigator.mediaDevices && navigator.mediaDevices.getUserMedia) {
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
await new Promise(resolve => {
videoElement.onloadedmetadata = () => {
resolve();
};
});
// Ajusta el tamaño del contenedor del video para mantener la relación de aspecto
const aspectRatio = videoElement.videoWidth / videoElement.videoHeight;
const videoContainer = document.getElementById('video-container');
videoContainer.style.paddingTop = `${100 / aspectRatio}%`;
webcam = await tf.data.webcam(videoElement);
statusElement.textContent = 'Cámara lista. Añade un objeto para empezar.';
} else {
statusElement.textContent = 'Error: Tu navegador no soporta la cámara web.';
}
} catch (error) {
console.error('Error al inicializar la aplicación:', error);
statusElement.textContent = 'Error: No se pudo cargar la cámara.';
}
}
- addClass():
Cada vez que el usuario añade un nuevo objeto, esta función crea un botón de captura en la interfaz. Lo más importante es que asocia el nombre del objeto (por ejemplo, «Lápiz») con un índice numérico (classIndex). Durante el entrenamiento, el modelo no trabaja con el texto «Lápiz», sino con el número que lo representa, lo cual es una práctica estándar en el aprendizaje automático.
function addClass() {
const className = classNameInput.value.trim();
if (className === '') {
statusElement.textContent = 'Por favor, escribe un nombre de objeto válido.';
return;
}
// Evita duplicados
if (classLabels.includes(className)) {
statusElement.textContent = `El objeto "${className}" ya existe.`;
return;
}
// Asigna un índice numérico para la clase
const classIndex = classLabels.length;
classLabels.push(className);
trainingData.push({ name: className, tensors: [] });
createCaptureButton(className, classIndex);
classNameInput.value = '';
}
- trainModel():
Esta es la función más crucial. Reúne todos los tensores (las representaciones numéricas de las imágenes capturadas) y las etiquetas numéricas en un solo conjunto de datos. Luego, define la arquitectura de la red neuronal convolucional (CNN) utilizando tf.sequential(), que apila diferentes capas (como conv2d para detectar características y maxPooling2d para reducir la dimensionalidad).
async function trainModel() {
const totalImages = trainingData.reduce((sum, cls) => sum + cls.tensors.length, 0);
if (trainingData.length < 2 || totalImages < 10) {
statusElement.textContent = 'Necesitas al menos 2 objetos y un total de 10 imágenes para entrenar.';
return;
}
trainButton.disabled = true;
predictButton.disabled = true;
statusElement.textContent = 'Entrenando modelo... Por favor, espera.';
// Concatenar todos los tensores de imágenes y etiquetas
const allTensors = tf.concat(trainingData.flatMap(cls => cls.tensors.map(t => t.tensor)));
const allLabels = tf.tidy(() => {
const labels = trainingData.flatMap(cls => cls.tensors.map(t => t.label));
return tf.oneHot(tf.tensor1d(labels, 'int32'), trainingData.length);
});
// Crea el modelo de clasificación con una arquitectura Keras personalizada
if (trainingModel) {
trainingModel.dispose();
}
// Define la arquitectura de la red neuronal convolucional
trainingModel = tf.sequential();
trainingModel.add(tf.layers.conv2d({
inputShape: [IMAGE_SIZE, IMAGE_SIZE, 3], // 64x64 pixeles, 3 canales de color (RGB)
kernelSize: 5,
filters: 8,
activation: 'relu',
}));
trainingModel.add(tf.layers.maxPooling2d({ poolSize: 2, strides: 2 }));
trainingModel.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
activation: 'relu',
}));
trainingModel.add(tf.layers.maxPooling2d({ poolSize: 2, strides: 2 }));
// Aplanar la salida de las capas convolucionales antes de las capas densas
trainingModel.add(tf.layers.flatten());
// Capa de salida densa con una unidad por cada clase
trainingModel.add(tf.layers.dense({
units: classLabels.length,
activation: 'softmax'
}));
trainingModel.summary();
// Compila el modelo
trainingModel.compile({
optimizer: 'rmsprop',
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
// Entrena el modelo con los datos capturados
await trainingModel.fit(allTensors, allLabels, {
epochs: 20, // Aumenta para mayor precisión, o reduce para un entrenamiento más rápido
shuffle: true,
callbacks: {
onEpochEnd: (epoch, logs) => {
console.log(`Epoch ${epoch + 1}: Loss = ${logs.loss.toFixed(4)}, Accuracy = ${logs.acc.toFixed(4)}`);
}
}
});
allTensors.dispose();
allLabels.dispose();
statusElement.textContent = 'Entrenamiento completado. ¡Puedes iniciar el reconocimiento!';
predictButton.disabled = false;
saveModelButton.disabled = false;
}
Gracias por estar atento a esta serie de tutoriales para aprender a hacer una aplicación web de reconocimientos de objetos utilizando TensorFlow.js y Keras.